Performance Trends in AI
**Edit To Add: **It’s been brought to my attention that I was wrong to claim that progress in image recognition is “slowing down”. As classification accuracy approaches 100%, obviously improvements in raw scores will be smaller, by necessity, since accuracy can’t exceed 100%. If you look at negative log error rates rather than raw accuracy scores, improvement in image recognition (as measured by performance on the ImageNet competition) is increasing roughly linearly over 2010-2016, with a discontinuity in 2012 with the introduction of deep learning algorithms.
Deep learning has revolutionized the world of artificial intelligence. But _how much _does it improve performance? How have computers gotten better at different tasks over time, since the rise of deep learning?
In games, what the data seems to show is that exponential growth in data and computation power yields exponential improvements in raw performance. In other words, you get out what you put in. Deep learning matters, but only because it provides a way to turn Moore’s Law into corresponding performance improvements, for a wide class of problems. It’s not even clear it’s a discontinuous advance in performance over non-deep-learning systems.
In image recognition, deep learning clearly is a discontinuous advance over other algorithms. But the returns to scale and the improvements over time seem to be flattening out as we approach or surpass human accuracy.
In speech recognition, deep learning is again a discontinuous advance. We are still far away from human accuracy, and in this regime, accuracy seems to be improving linearly over time.
In machine translation, neural nets seem to have made progress over conventional techniques, but it’s not yet clear if that’s a real phenomenon, or what the trends are.
In natural language processing, trends are positive, but deep learning doesn’t generally seem to do better than trendline.
Chess
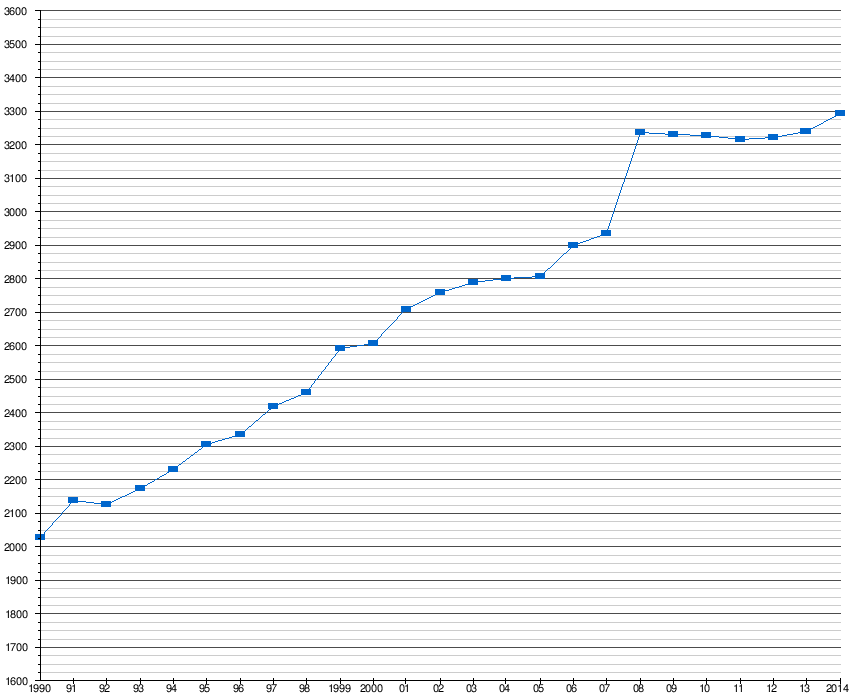
These are Elo ratings of the best computer chess engines over time.
There was a discontinuity in 2008, corresponding to a jump in hardware; this was the Rybka 2.3.1, a tree-search-based engine without any deep learning or indeed probabilistic elements. Apart from that, progress looks roughly linear.
Here again is the Swedish Chess Computer Association data on Elo scores over time:
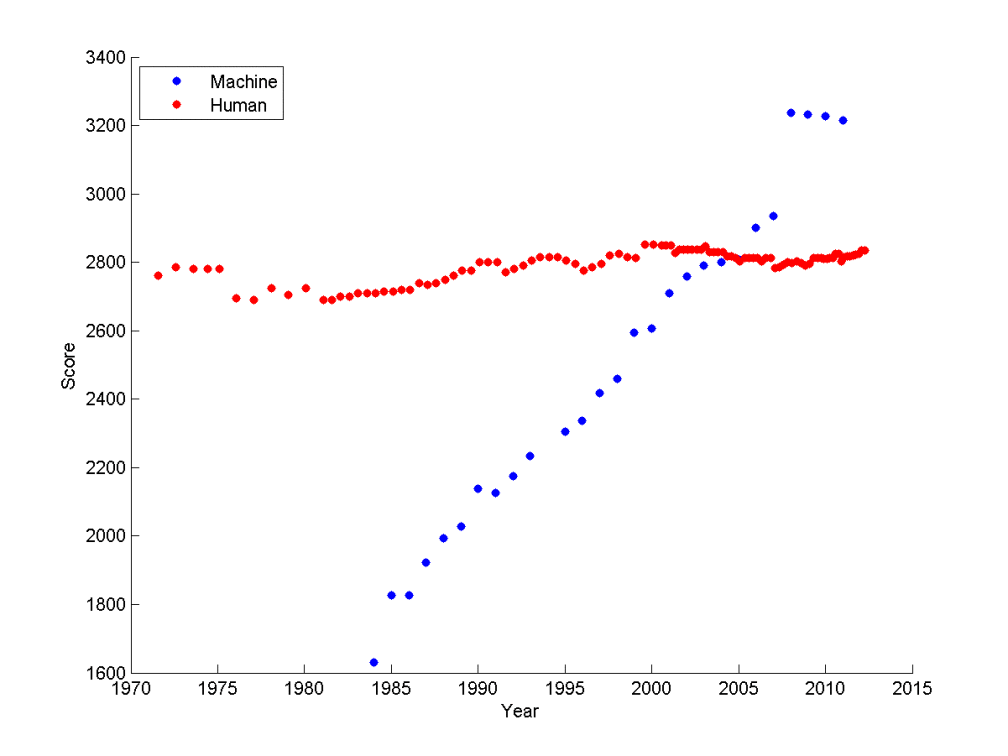
Deep learning chess engines have only just recently been introduced; Giraffe, originated by Matthew Lai at Imperial College London, was created in 2015. It only has an Elo rating of 2412, about equivalent to late-90’s-era computer chess engines. (Of course, learning to predict patterns in good moves probabilistically from data is a more impressive achievement than brute-force computation, and it’s quite possible that deep-learning-based chess engines, once tuned over time, will improve.)
Go
(Figures from the Nature paper on AlphaGo.)
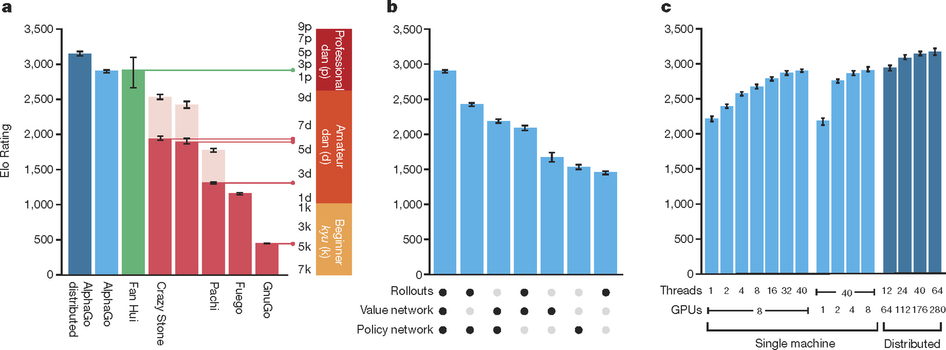
Fan Hui is a human player. Alpha Go performed notably better than its predecessors Crazy Stone (2008, beat human players in mini go games), Pachi (2011), Fuego (2010), and GnuGo, all MCTS programs, but without deep learning or GPUs. AlphaGo uses _much _more hardware and more data.
Miles Brundage has argued that AlphaGo doesn’t represent that much of a surprise given the improvements in hardware and data (and effort). He also graphed the returns in Elo rating to hardware by the AlphaGo team:
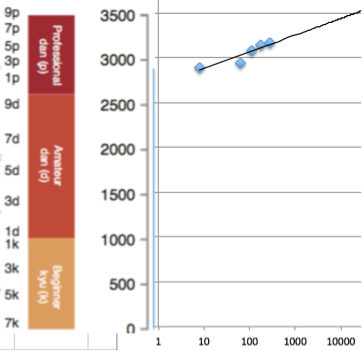
In other words, _exponential _growth in hardware produces only roughly _linear _(or even sublinear) growth in performance as measured by Elo score. To do better would require algorithmic innovation as well.
Arcade Games
Artificial Atari games are scored relative to a human professional playtester: (Computer score – random play)/(Human score – random play).
Compare to Elo scores: the ratio of expected scores for player A vs. player B is Q_A / Q_B, where Q_A = 10^(E_A/400), E_A being the Elo score.
Linear growth in Elo scores is equivalent to exponential growth in absolute scores.
Miles Brundage’s blog also offers a trend in Atari performance that looks exponential:
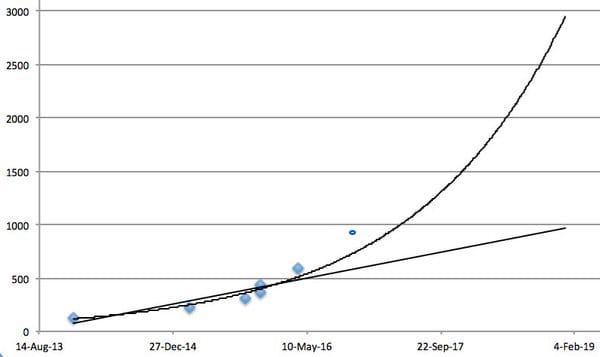
This would, of course, still be plausibly linear in Elo score.
Superhuman performance at arcade games is already here:
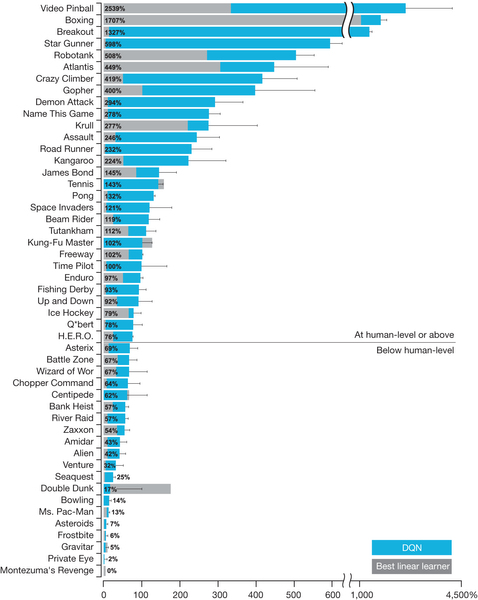
This was a single reinforcement learner trained with a convolutional neural net over images of the game screen outputting behaviors (arrows). Basically it’s dynamic programming, with a nonlinear approximation of the Q-function that estimates the quality of a move; in Deepmind’s case, that Q-function approximator is a convolutional neural net. Apart from the convnet, Q-learning with function approximation has been around since the 90’s and Q-learning itself since 1989.
Interestingly enough, here’s a video of a computer playing Breakout:
https://www.youtube.com/watch?v=UXgU37PrIFM
It obviously doesn’t “know” the law of reflection as a principle, or it would place the bar near where the ball will eventually land, and it doesn’t. There are erratic jerky movements that obviously could not in principle be optimal. It does, however, find the optimal strategy of tunnelling through the bricks and hitting the ball behind the wall. This is _creative _learning but not _conceptual _learning.
You can see the same phenomenon in a game of Pong:
https://www.youtube.com/watch?v=YOW8m2YGtRg
The learned agent performs much better than the hard-coded agent, but moves more jerkily and “randomly” and doesn’t know the law of reflection. Similarly, the reports of AlphaGo producing “unusual” Go moves are consistent with an agent that can do pattern-recognition over a broader space than humans can, but which doesn’t find the “laws” or “regularities” that humans do.
Perhaps, contrary to the stereotype that contrasts “mechanical” with “outside-the-box” thinking, reinforcement learners can “think outside the box” but can’t find the box?
ImageNet
Image recognition as measured by ImageNet classification performance has improved dramatically with the rise of deep learning.
.png)
There’s a dramatic performance improvement starting in 2012, corresponding to Geoffrey Hinton’s winning entry, followed by a leveling-off. Plausibly accuracy is an S-shaped curve.
How does accuracy scale with processing power?
This paper from Baidu illustrates:
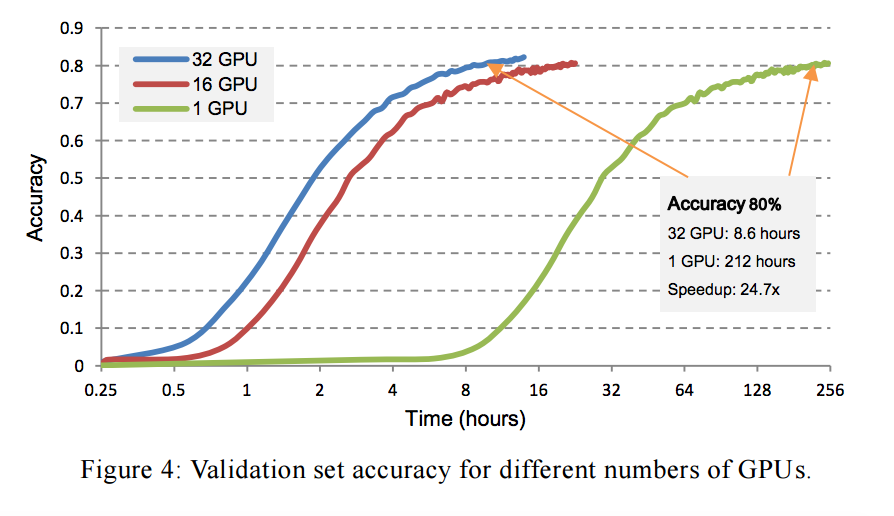
The performance of a deep neural net follows an S-shaped curve over time spent training, but works faster with more GPUs. How much faster?
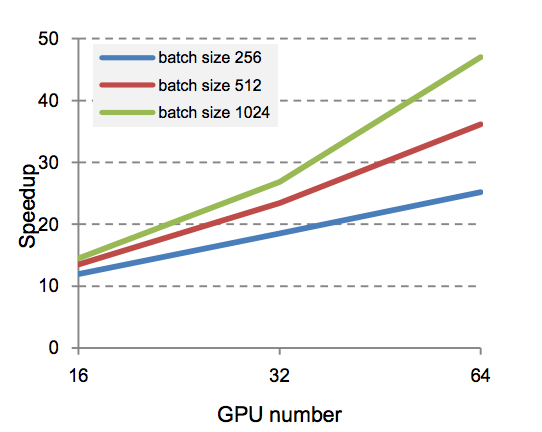
Each doubling in GPUs provides only a linear boost in speed. At a _given _time interval for training (as one would have in a timed competition), this means that doubling the number of GPUs would result in a sublinear boost in accuracy.
MNIST
.png)
Using the performance data from Yann LeCun’s website, we can see that deep neural nets hugely improved MNIST digit recognition accuracy. The best algorithms of 1998, which were convolutional nets and boosted convolutional nets due to LeCun, had error rates of 0.7-0.8. Within 5 years, that had dropped to error rates of 0.4, within 10 years, to 0.39 (also a convolutional net), within 15 years, to 0.23, and within 20 years, to 0.21. Clearly, performance on MNIST is leveling off; it took five years to halve and then 20 years to halve again.
As with ImageNet, we may be getting close to the limits of deep-learning performance (which may easily be human-level.)
Speech Recognition
Before the rise of deep learning, speech recognition was already progressing rapidly, though it was leveling off in conversational speech well above the 10% accuracy rate.
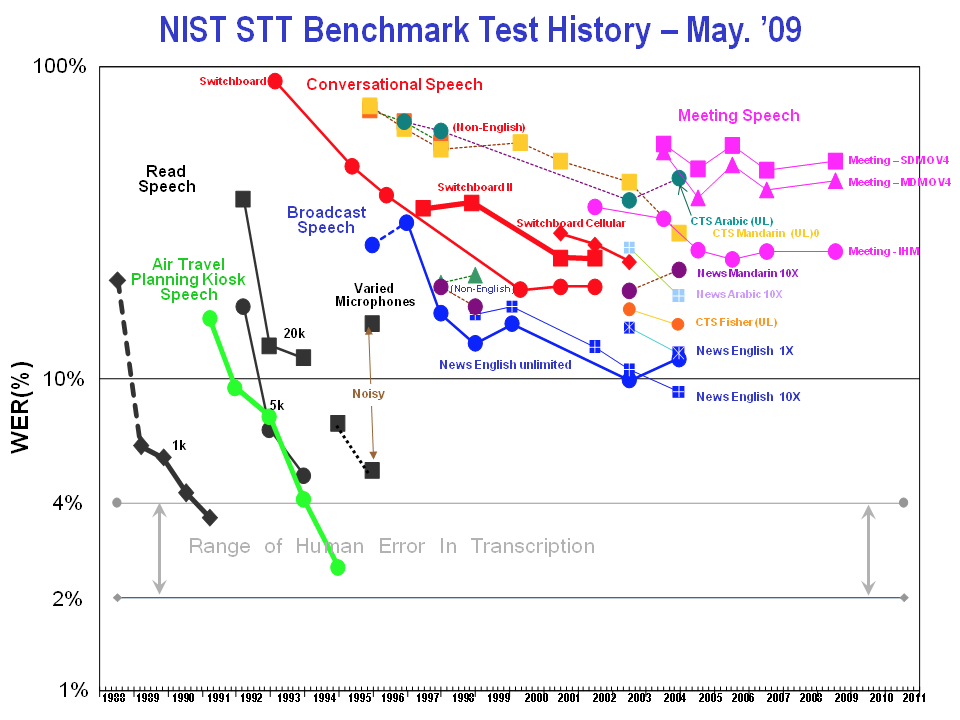
Then, in 2011, the advent of context-dependent deep neural network hidden Markov models produced a discontinuity in performance:
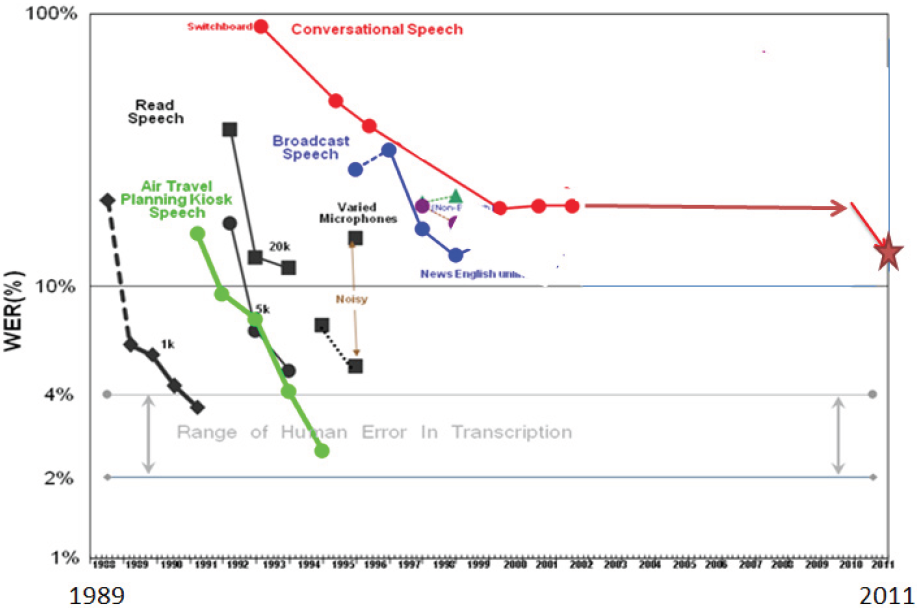
More recently, accuracy has continued to progress:
Nuance, a dictation software company, shows steadily improving performance on word recognition through to the present day, with a plausibly exponential trend.
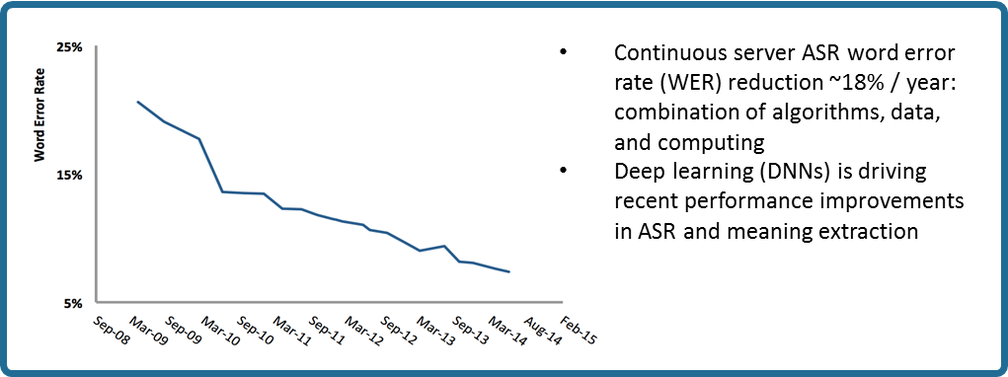
Baidu has progressed even faster, as of 2015, in speech recognition on Mandarin.
As of 2016, the best performance on the NIST 2000 Switchboard set (of phone conversations) is due to Microsoft, with a word-error rate of 6.3%.
Translation
Machine translation is evaluated by BLEU score, which compares the translation to the reference via overlap in words or n-grams. BLEU scores range from 0 to 1, with 1 being perfect translation. As of 2012, Tilde’s had BLEU scores in the 0.25-0.45 range, with Google and Microsoft performing similarly but worse.
In 2016, Google came out with a new neural-network-based version of its translation tool. BLEU scores on English -> French and English -> German were 0.404 and 0.263 respectively. Human evaluations, however, rated the neural machine translations 60-87% better.
OpenMT, the machine translation contest, had top BLEU scores in 2012 of about 0.4 for Arabic-to-English, 0.32 for Chinese-to-English, 0.24 for Dari-to-English, 0.27 for Farsi-to-English, and 0.11 for Korean-to-English.
In 2008, Urdu-to-English had top BLEU scores of 0.32, Arabic-to-English scores of 0.48, and Chinese-to-English scores of 0.30.
This doesn’t correspond to an improvement in machine translation at all. Apart from Google’s improvement in human ratings, celebrated in this New York Times Magazine article, it’s unclear whether neural networks actually improve BLEU scores at all. On the other hand, scoring metrics may be an imperfect match to translation quality.
Natural Language Processing
The Association for Computational Linguistics Wiki has some numbers on state of the art performance for various natural language processing tasks.
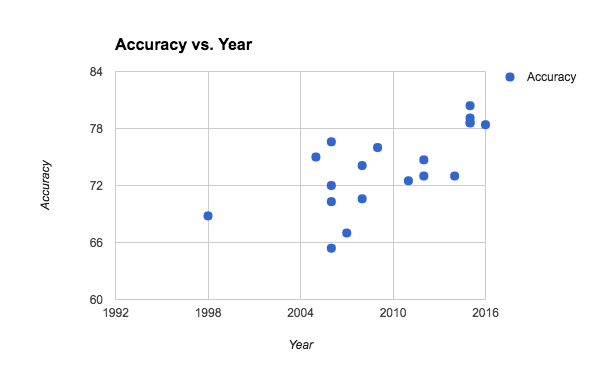
SAT analogies have been becoming more accurate over time, roughly linearly, until the present day when they are roughly as accurate as the average US college applicant. None of these are deep learning techniques.
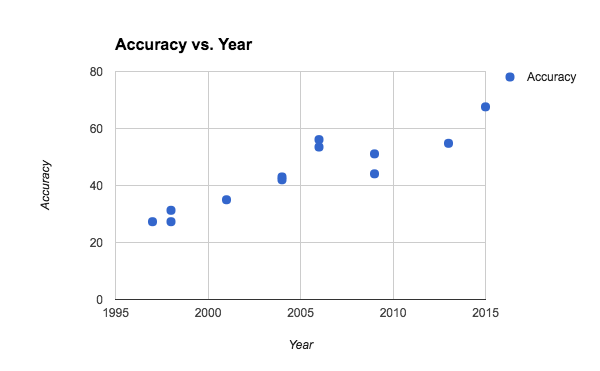
Question answering (multiple choice of sentences that answer the question) has improved roughly steadily over time, with a discontinuity around 2006. Neural nets did not start being used until 2014, but were _not _a discontinuous advance from the best models of 2013.
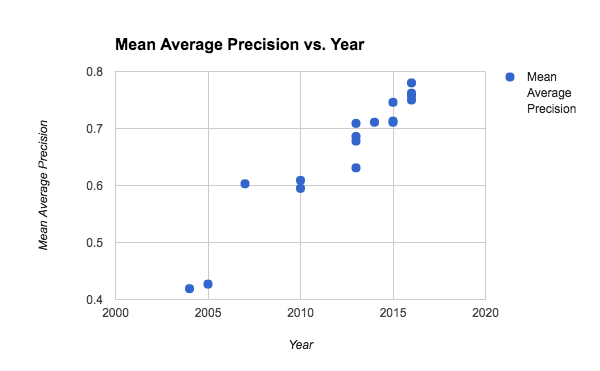
Paraphrase identification (recognizing if one paragraph is a paraphrase of another) seems to have risen steadily over the past decade, with no special boost due to deep learning techniques; the top performance is not from deep learning but from matrix factorization.
On NLP tasks that have a long enough history to graph, there seems to be no clear indication that deep learning performs above trendline.
Trends relative to processing power and time
Performance/accuracy returns to processing power seem to differ based on problem domain.
In image recognition, we see _sublinear _returns to linear improvements in processing power, and gains leveling off over time as computers reach and surpass human-level performance. This may mean simply that image recognition is a nearly-solved problem.
In NLP, we see roughly linear improvements over time, and in machine translation, it’s unclear if we see _any _trends in improvements over time, both of which suggest sublinear returns to processing power, but this is not very confident.
In games, we see roughly _linear _returns to linear improvements in processing power, which means exponential improvements in performance over time (because of Moore’s law and increasing investment in AI).
This would suggest that far-superhuman abilities are more likely to be possible in game-like problem domains.
What does this imply about deep learning?
What we’re seeing here is that deep learning algorithms can provide improvements in narrow AI across many types of problem domains.
Deep learning provides discontinuous jumps relative to previous machine learning or AI performance trendlines in image recognition and speech recognition; it doesn’t in strategy games or natural language processing, and machine translation and arcade games are ambiguous (machine translation because metrics differ; arcade games because there is no pre-deep-learning comparison.)
A speculative thought: perhaps deep learning is best for problem domains oriented around sensory data? Images or sound, rather than symbols. If current neural net architectures, like convolutional nets, mimic the structure of the sensory cortex of the brain, which I think they do, one would expect this result.
Arcade games would be more analogous to the motor cortex, and perceptual control theory suggests that something similar to Q-learning may be going on in motor learning, though I’d have to learn more to be confident in that. If mammalian motor learning turns out to look like Q-learning, I’d expect deep reinforcement learning to be especially good in arcade games and robotics, just as deep neural networks are especially good in visual and audio classification.
Deep learning hasn’t really proven itself better than trendline in strategy games (Go and chess) or in natural language tasks.
I might wonder if there are things humans can do with concepts and symbols and principles, the traditional tools of the “higher intellect”, the skills that show up on highly g-loaded tasks, that deep learning cannot do with current algorithms. Obviously hard-coding rules into an AI has grave limitations (the failure of such hard-coded systems was what caused several of the AI winters), but there may also be limitations to non-conceptual pattern recognition. The continued difficulty of automating language-based tasks may be related to this issue.
Miles Brundage points out,
_Progress so far has largely been toward demonstrating general approaches for building narrow systems rather than general approaches for building general systems. Progress toward the former does not entail substantial progress toward the latter. The latter, which requires transfer learning among other elements, has yet to have its Atari/AlphaGo moment, but is an important area to keep an eye on going forward, and may be especially relevant for economic/safety purposes._
I agree. General AI systems, as far as I know, do not exist today, and the million-dollar question is whether they can be built with algorithms similar to those used today, or if there are further fundamental algorithmic advances that have yet to be discovered. So far, I think there is no empirical evidence from the world of deep learning to indicate that today’s deep learning algorithms are headed for general AI in the near future. Discontinuous performance jumps in image recognition and speech recognition with the advent of deep learning are the most suggestive evidence, but it’s not clear whether those are above and beyond returns to processing power. And so far I couldn’t find any estimates of trends in cross-domain generalization ability. Whether deep learning algorithms _can _be general-purpose is perhaps a more theoretical question; what we can say is that recent AI progress doesn’t offer any reason to suspect that they already are.